


关于爬虫中几个常用库的使用方法总结

关于爬虫中几个常用库的使用方法总结
- 学了半个多月的爬虫了,用这个案例总结一下各个爬虫库的用法。当然后面还有更重要和更好用的方法,再等后面学到,再做总结了。
1. 目标
- 这个题目的要求很简单,用已学的方法,爬取某知名二手房源的信息。因为涉及到一些敏感的信息,只要求获取只个简单的字段即可。
1.1 爬取某知名网站的相关信息
- 具体如下:
- (1)爬取某网的房源信息,包括“标题,位置,户型,总价,单价”几个信息的收集并保存。
- (2)网址是:https://cs.lianjia.com/ershoufang/
1.2 信息库及类的导入
- 下面分几种方法解决这个答题,所以用到的库有如下几种:
- requests、lxml的xpath对象方法、re正则表达式、BeautifuSoup对象方法、pyquery对象方法、parsel的Selector方法
- 有时候,获取源代码和解析数据,是好几种方法一起来解决,在下面的几个解决方案中,都有提到。
2. 网页分析
- 接下来,就是网页的分析。打开网页如下:
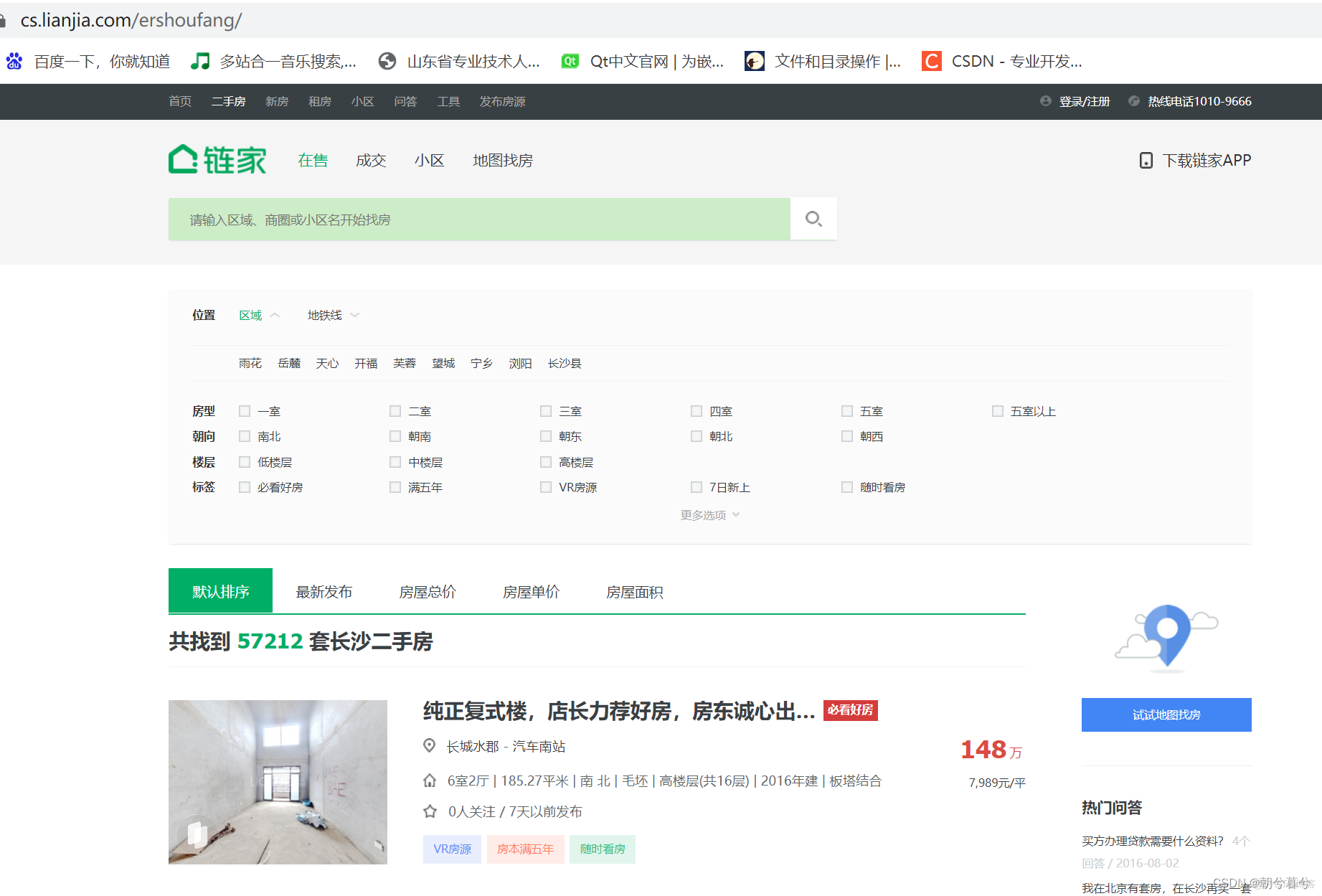
- 再往下拖动,看到该页有30条信息,下面只看到局部的几条信息。其中每一条信息用蓝色方框圈起来,而红色方框圈起来的,是一条广告信息,是无用信息,后面在解析的时候给予剔除。

2.1 伪装问题
- 根据政策法规的要求,我们不能随便用不正当手段爬取绝大多数网站的有用信息。不过动机单纯、行为正常,且没有恶意,出于研究目的,在控制好频率的情况下,爬取一些网站公开内容,是可以的。
- 但是绝大多数网站都有反爬机制,它不管你的动机如何,一旦越限,它就会毫不客气的唯你是问,让你百口莫辩。
- 因此,我们在这里,也了解一下这次这个网站的Robots协议,方法如下:
- 打开https://cs.lianjia.com/robots.txt,得到如下robots内容:
User-agent: Baiduspider Allow: *?utm_source=office* User-agent: * sitemap: https://cs.lianjia.com/sitemap/cs_index.xml Disallow: /rs Disallow: /huxingtu/p Disallow: /user Disallow: /login Disallow: /userinfo Disallow: *?project_name=* Disallow: *?id=* Disallow: *?house_codes=* Disallow: *?sug=* - 以上可以看到,我们今天所要爬取的目录ershoufang是被允许爬取的。
- 再用如下方法:

- 可以看到,这个网站的robots.txt文件是允许爬虫抓取ershoufang里面的数据的。
- 基于以上原因,我们只加一个请求头,是可以了。方法前面写过:右击网页空白处“检查”——>“Network”——>Filter(筛选器)——>Doc(文档)——>刷新网页——>选择Name(名称)下的记录——>再找到右侧最底部,就找到User-Agent字符串头。复制出来 做成字典的模样,定义一个headers即可。

- 打开https://cs.lianjia.com/robots.txt,得到如下robots内容:
2.2 元素选取
- 上图说明,如下:

- 左侧小箭头就是选择器,使用的时候点它一下,然后去网页里面晃动几下,就看到一片区域对应一大段代码。这里,我们看到
- 标签里,就对应本页所有的房源信息,就是
- 标签,仔细数一下,一共30条记录,对应30条房源,当然,其中第6条是广告,不过在爬虫库解析下,得到的数据是一一对应为30条的。
- 每一条的标签下,都包含我们想要的数据,截图如下:', re.S) priceInfo_pattern = re.compile('class="totalPrice totalPrice2">.*?class="">(.*?).*?', re.S) unitPrice_pattern = re.compile('class="unitPrice.*?(.*?)', re.S) title = re.search(title_pattern, htmlStr).group(1) position = re.search(position_pattern, htmlStr) positiongroup = position.group(1) + position.group(2) houseInfo = re.search(houseInfo_pattern, htmlStr).group(1) priceInfo = re.search(priceInfo_pattern, htmlStr).group(1) +"万元" unitPrice = re.search(unitPrice_pattern, htmlStr).group(1) # 注意,下面字典处理的时候,一定要用""而不能用'' yield {"标题": title, "位置": positiongroup, "户型": houseInfo, "总价": priceInfo, "单价": unitPrice} except IndexError: pass def write_data(self, content): with open('链家长沙房源信息.txt', 'a',encoding='utf-8') as f: # 因为获取的数据是字典类型,转换为字符串写入文本文件,而且还不能显示为ascii,否则看不到汉字 f.write(json.dumps(content,ensure_ascii=False)+"\n") """ 3. 把上面方法整合起来完成业务逻辑""" def run(self): resp = self.get_data_index() # 获取网页信息 for data in self.parse_data_index(resp): print(data) self.write_data(data) if __name__ == '__main__': # 爬取5页的数据 for n in range(1, 6): print('正在爬取第{}页'.format(n)) spider = LianJian_changsha(n) spider.run()

2.3 分页面分析
- 页面到最底部,有1到100页码,所以想抓取的信息可以有100页300条,本例只取前5页,用for循环实现翻页取信息,在下面代码实现。因为在翻页的过程中,地址栏里出现/pg2/、/pg3/的字样。所以在定义网址的时候,用如下方法:
…def __init__(self, num): self.url = 'https://cs.lianjia.com/ershoufang/pg{}/'.format(num)# 爬取5页的数据 for n in range(1, 6): print('正在爬取第{}页'.format(n)) spider = LianJian_changsha(n)
2.3 爬虫库的选用
- 一般情况下,爬取数据不是太多的时候,用requests库结合一般的方法就能完成,大型数据获取并分析的情况,要用到更高级的方法。所以根据需求选择合适的爬虫库,也应该知道。因为是初学,对于下面的分析不一定准确,欢迎编程经验多的大佬们,批评指正。
2.3.1 保存文本的方法
-
除了即时打印输出到控制台的办法外,保存爬虫数据最基础的自然是文本文件了。
-
方法很简单,就是用操作文件和文件夹的办法,实现保存。涉及到路径的时候,要导入os库,然后有两种书写格式,如下 :
# 第一种方法,后面需要手动close关闭文件对象 filename = open('file1.txt','w') filename.close()…
# 第二种方法,后面不需要带close方法,也可以确保文件正常关闭 with open('file2.txt','w') as f2: f2.write(data)
2.3.2 保存二进制的方法
- 上面提到,文本文件的获取过程,首先是获取源代码,再解析筛选得到文本内容,如果想要的数据变量为data的话,可以用text方法得到,如print(data.text)。而要得到图像或者音视频数据的话,就要先得到它们的二进制数据,用content方法,如print(data.content)。
- 后面例子中,会经常遇到,爬虫学习的过程中,有你有我,我们一起作伴,慢慢走在路上,就会不知疲倦。
2.3.3 哪个更简单
- 哪个爬虫的库用起来更简单,也要看获取到的网页格式,像本节提到的例子,用lxml里面的xpath方法比较简单。我说的简单,其实就是容易理解和使用,真正书写代码也可能很繁琐。我们在验证结果的时候,要不时的print一下,以此纠正解析得到的数据是多了还是少了。
- 如果按照书写简洁来作为简单的话,目前学到的bs4和pyquery库就特别简单。很多时候,感觉比正则表达式的方法还要简单。
2.3.4 哪个更效率
- 效率最高的爬虫方法,目前不敢定论,但是感觉requests以后,再用xpath方法是最麻烦的,遇到源代码中的多个ul列表、li列表、span列表等,还有各种空格乱码时,特快灵麻烦。在掌握了好的方法和熟练运用正则表达式之后,xpath能不用就不用,但是本节还是以这个为例讨论,毕竟这个是基础。
- 我感觉,bs4和pyquery效率就蛮高,但是感觉目前掌握的方法中parsel方法更胜一筹。
- 除了上面提到的,还有一个压箱底的东西,那就是CSS选择器,这个东西在几个重要的爬虫库里面经常用到,而且经常一步到位,实在是手术刀式的工具。
2.4 数据保存的问题
-
- 爬虫得到的结果,才是我们想要的。有的不是太重要,可以略加展示或保存。有的结果很重要,这些数据就要用相当可靠的方式保存起来,以供后期的分析和使用。
2.4.1 打印输出
- 这是最简单的展示方法,只是在控制台打印输出一下,看完就消失,对于不是重要的信息,完全够用了。
2.4.2 文本保存
- 爬虫获取的数据,以最简单的文本格式保存,上面已经提到,后面复习爬虫库的使用时,还会再提到 ,在此不再赘述。
2.4.3 csv文件存储
- 我用excel格式保存数据的时候,遇到了不能保存翻页信息的情况,当掌握了csv文件存储方法后,一下子感觉轻松解决了。因为csv文件完全可以用excel表格的形式打开,而且更简洁效率。
2.4.4 MySql存储
- 这个数据库用来存储数据,是比较哪个和哪个的(敏感词&^%#@¥),不光是因为MySql在大型程序中应用,关键是很多爬虫得到的数据足够重要,用MySql保存也足够正式。这为后面的数据分析作了良好的支持。
2.4.5 MongoDB存储
- 这个数据库是非关系型数据库,其内容存储的形式累死JSON对象。这次也学习一下这个数据库的保存方式,这之前要从头学习它的安装、初始化和建表、插入数据的方法。
3. 方法罗列
下面的几种爬虫方法是目前我个人学到的,为了帮助记忆理解,在此加以记叙和总结。其中发现,各种方法很少有单独存在的情况,一是因为一个方法完成不了,另一个原因是,几种方法的组合使用,效率大大提高。
3.1 requests方法
- 这个方法,是后面xpath方法、re正则表达式的前提条件。因为都用requests模块的get请求方法和post请求方法得到整个网页源代码之后,再进行xpath解析和正则匹配的。实际用法,在后面放上案例进行学习。
3.2 lxml的xpath方法
- 按照上面的分析,用代码实现目标要求。全部代码如下:
# -*- coding:utf-8 -*- """ # @Time:2022/12/19 0019 13:53 # @Author:晚秋拾叶 # @File:链家长沙房源.py # @PyCharm之Python # 完成“标题,位置,户型,总价,单价”几个信息的收集并保存 """ import os import csv import requests from lxml import etree class LianJian_changsha(object): def __init__(self, num): self.url = 'https://cs.lianjia.com/ershoufang/pg{}/'.format(num) self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54', } ''' 1. 发起请求并获取数据 ''' def get_data_index(self): # 可以使用urlli库里的方法from urllib.request import Request # 即用urllib中的request模块里的Request类定义解析的网页数据, # 不过需要用read()读取二进制内容,再用decode('utf-8')转为Unicode编码 # 所以不如requests库来得方便 """ (1)用到第一个库requests的get方法,获取总的网页源代码 """ resp = requests.get(self.url, headers=self.headers) resp.encoding = 'utf-8' if resp.status_code == 200: return resp.text else: return None ''' 2. 把得到的网页文本信息进行解析 ''' def parse_data_index(self, resp): # 实例化一个etree的HTML类对象,这也是后面xpath解析的对象 """ (2)用到第二个库lxml里的etree模块,构造一个xpath对象 """ html_xpath = etree.HTML(resp) # 找到包含房源信息的总模块,可以看作为列表形式 """ (3)xpath方式完成解析数据 """ sellListContent = html_xpath.xpath('//ul[@class="sellListContent"]//li') list_context = [] i = 0 for data in sellListContent: title = data.xpath('.//div[@class="title"]/a/text()')[0] position = ','.join(data.xpath('./div[1]/div[2]//a/text()')).replace(' ', '') houseInfo = data.xpath('.//div[@class="houseInfo"]/text()')[0].replace('|', ',').replace(' ', '') priceInfo = data.xpath('.//div[contains(@class,"totalPrice")]/span/text()')[0] + "万元" unitPrice = data.xpath('.//div[@class="unitPrice"]/span/text()')[0] dict_data = {'标题': title, '位置': position, '户型': houseInfo, '总价': priceInfo, '单价': unitPrice} i += 1 print(f"现在是第{i}条数据") print(dict_data) list_context.append(dict_data) return list_context def write_data(self, resp): # 判断是否已经有这个csv文件,如果有,则不再添加标头,只追加记录 if os.path.exists("LianJia_changsha.csv"): with open("LianJia_changsha.csv", "a", newline='', encoding='utf-8') as f: fields = ['标题', '位置', '户型', '总价', '单价'] writer = csv.DictWriter(f, fieldnames=fields) for data in self.parse_data_index(resp): writer.writerow(data) else: with open("LianJia_changsha.csv", "w", newline='', encoding='utf-8') as f: fields = ['标题', '位置', '户型', '总价', '单价'] writer = csv.DictWriter(f, fieldnames=fields) writer.writeheader() for data in self.parse_data_index(resp): writer.writerow(data) """ 3. 把上面方法整合起来完成业务逻辑""" def run(self): resp = self.get_data_index() # 获取网页信息 self.write_data(resp) if __name__ == '__main__': # 爬取5页的数据 for n in range(1, 6): print('正在爬取第{}页'.format(n)) spider = LianJian_changsha(n) spider.run()- 掌握了合适的方法,加以处理,就得到了想要的数据,其中的带广告的那个li标签,也合理的规避了。上面这个方法用了csv格式保存
3.3 re正则表达式
- 下面是用re正则表达式的方法完成问题解决。还是先用xpath缩小一下源代码的范围,做出
- 标签的列表来。在用re处理字符串的过程中,遇到了检查元素的代码和xpath获取源代码不一样的情况。如图:
- 检查元素的代码:

- 由此可见,想要正则匹配到我们需要的数据,只有得到真正的源代码才能够获取。下面用requests和xpath方法得到li标签列表。

- 上面截图是爬取到的li标签列表,复制出一个li标签到http://www.wetools.com/html-formatter网站,稍微纠正下,再复制到记事本里面,更容易寻找对应的数据。

- 下面把得到的源代码放到记事本中。

- 再把包含一个数据的一大段代码复制到VSCode程序里,加以正则处理。

- 注意想要的数据用(.*?)代替,然后方便用group(n)的方法得到。

- 在保存为字符串形式的时候,需要一些转换字典为字符串的情况,代码中已经作了注释。
- 最后,我把这个用记事本保存成txt文件,整个代码如下:
# -*- coding:utf-8 -*- """ # @Time:2022/12/19 0019 13:53 # @Author:晚秋拾叶 # @File:链家长沙房源.py # @PyCharm之Python # 完成“标题,位置,户型,总价,单价”几个信息的收集并保存 """ import os import re import json import requests from lxml import etree class LianJian_changsha(object): def __init__(self, num): self.url = 'https://cs.lianjia.com/ershoufang/pg{}/'.format(num) self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54', } ''' 1. 发起请求并获取数据 ''' def get_data_index(self): # 可以使用urlli库里的方法from urllib.request import Request # 即用urllib中的request模块里的Request类定义解析的网页数据, # 不过需要用read()读取二进制内容,再用decode('utf-8')转为Unicode编码 # 所以不如requests库来得方便 """ (1)用到第一个库requests的get方法,获取总的网页源代码 """ resp = requests.get(self.url, headers=self.headers) resp.encoding = 'utf-8' if resp.status_code == 200: return resp.text else: return None ''' 2. 把得到的网页文本信息进行解析 ''' def parse_data_index(self, resp): # 进一步筛选想要的源代码内容,缩小范围 """ (2)还是用xpath定位好范围 """ html_xpath = etree.HTML(resp) sellListContent = html_xpath.xpath('//ul[@class="sellListContent"]//li') try: """ (3)re正则方式完成解析数据 """ for data in sellListContent: # 转换为字符串,以便后面进行正则获取 htmlStr = etree.tostring(data,encoding="utf-8").decode() title_pattern = re.compile('
- 页面到最底部,有1到100页码,所以想抓取的信息可以有100页300条,本例只取前5页,用for循环实现翻页取信息,在下面代码实现。因为在翻页的过程中,地址栏里出现/pg2/、/pg3/的字样。所以在定义网址的时候,用如下方法:
- 完成后,效果如下:

下的 3.4 BeautifuSoup方法
- 再学习一下bs4的写法。
- 这个库的功能很强大,方法有节点选择器,有方法选择器find_all,再加上强大的CSS选择器。用了更简短的代码,完成了既定目标。完整代码如下:
# -*- coding:utf-8 -*- """ # @Time:2022/12/19 0019 13:53 # @Author:晚秋拾叶 # @File:链家长沙房源bs4.py # @PyCharm之Python # 完成“标题,位置,户型,总价,单价”几个信息的收集并保存 # 这次用excel方法保存 """ import requests import openpyxl from bs4 import BeautifulSoup class LianJian_changsha(object): def __init__(self): self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54', } ''' 1. 发起请求并获取数据 ''' def get_response(self,url): # 可以使用urlli库里的方法from urllib.request import Request # 即用urllib中的request模块里的Request类定义解析的网页数据, # 不过需要用read()读取二进制内容,再用decode('utf-8')转为Unicode编码 # 所以不如requests库 来得方便 """ (1)用到第一个库requests的get方法,获取总的网页源代码 """ resp = requests.get(url, headers=self.headers) resp.encoding = 'utf-8' if resp.status_code == 200: return resp.text else: return None ''' 2. 把得到的网页文本信息进行解析 ''' def parse_data(self): data_list = [] for i in range(1,6): # 因为要分布保存到excel中,而且用的是openpyxl方法,所以把页面地址的更迭放在这里 url = 'https://cs.lianjia.com/ershoufang/pg{}/'.format(i) resp = self.get_response(url) # 进一步筛选想要的源代码内容,缩小范围 """ (2)这个库的功能强大,用select方法和节点选择器,加上CSS选择器,代码简洁好用 """ soup = BeautifulSoup(resp, 'lxml') sellListContent = soup.select("ul li .info.clear") i = 0 # 解析并提取数据 for data_div in sellListContent: # 下面的[0]用法,其实是列表索引,与xpath的位置选择不一样 title= data_div.select("a")[0].text position = data_div.select("div .positionInfo")[0].text houseInfo = data_div.select("div .houseInfo")[0].text priceInfo = data_div.select(".totalPrice.totalPrice2 span")[0].text + "万元" unitPrice = data_div.select(".unitPrice")[0].text data = [title,position,houseInfo,priceInfo,unitPrice] i += 1 print(f"现在是第{i}条") print(data) data_list.append(data) return data_list def save_to_excel(self): datas = self.parse_data() #数据,也就是上面获取到的嵌套列表 print('开始保存...') # 表头 excel_header = ['标题','位置','户型','总价','单价'] # 创建excel表格并写入表头 wb = openpyxl.Workbook() ws = wb.create_sheet(title='链家长沙房源', index=0) wb.remove(wb['Sheet']) # 删除原来的表 ws.append(excel_header) # 写入表头 # 遍历数据 for data in datas: # 将每行数据追加到表格 ws.append(data) # 保存表格 wb.save('链家长沙房源.xlsx') """ 3. 把上面方法整合起来完成业务逻辑""" def run(self): self.parse_data() # 获取网页信息 self.save_to_excel() print("保存完成。") if __name__ == '__main__': spider = LianJian_changsha() spider.run() - 效果如图。

3.5 pyquery方法
- 这次保存数据信息,我用MySQL的方法,以进一步掌握数据库的使用方法。
3.5.1安装MySQL
-
这里登录https://dev.mysql.com/downloads/mysql/,选择Microsoft Windows打开如下页面,点击下面的Download按钮。

-
这是一个免安装的数据库程序,然后把数据库包解压到E盘,如图。

-
其中,my.ini是自己创建的配置文件,保存到数据库当前目录,内容如下:
[client] # 设置mysql客户端默认字符集 default-character-set=utf8 [mysqld] # 设置3306端口 port = 3306 # 设置mysql的安装目录 basedir=E:\mysql8.0 # 设置 mysql数据库的数据的存放目录,MySQL 8+ 不需要以下配置,系统自己生成即可,否则有可能报错 # datadir=E:\mysql8.0\\sqldata # 允许最大连接数 max_connections=20 # 服务端使用的字符集默认为8比特编码的latin1字符集 character-set-server=utf8 # 创建新表时将使用的默认存储引擎 default-storage-engine=INNODB -
接下来我们来启动下 MySQL 数据库:
- 以管理员身份打开 cmd 命令行工具,切换目录:

3.5.1 初始化数据库
~~~ mysqld --initialize --console ~~~执行完成后,会输出 root 用户的初始默认password,如:
... 2023-01-04T02:35:05.464644Z 5 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: APWCY5ws&hjQ ...APWCY5ws&hjQ 就是初始password,后续登录需要用到,你也可以在登陆后修改password。
mysqladmin -u用户名 -p旧密 password 新密 我这里没有成功,也没找原因,直接去掉旧密,再执行后,要求输入password的时候,输入完就更新成功了。最后显示OK。
-
安装数据库,下面也是在bin目录下执行。
mysqld install
-
安装结束后启动服务即可, 启动服务命令如下:
net start mysql -
登陆MySQL
当 MySQL 服务已经运行时, CD到bin目录,打开命令提示符, 输入以下格式的命名:
mysql -h 主机名 -u 用户名 -p- -h : 指定客户端所要登录的 MySQL 主机名, 登录本机(localhost 或 127.0.0.1)该参数可以省略;
- -u : 登录的用户名;
- -p : 告诉服务器将会使用一个password来登录, 如果所要登录的用户名password为空, 可以忽略此选项。
-
查看数据库
语法:
show databases; -
创建数据库
语法:
create database 库名;这里创建一个名字为lianjia的库名。
-
创建数据表,下面命令,可以在console窗口Mysql提示符下录入,也可以在idle的sql控制台下录入,都可以。 语法:
create table lianjia_cs ( id int auto_increment, title varchar(100) null, position varchar(200) null, houseInfo varchar(200) null, priceInfo varchar(50) null, unitPrice varchar(50) null, primary key(id) )DEFAULT CHARSET=utf8;
3.5.3 数据库与idle的连接操作
- 用VSCode连接MySQL8.0,步骤如下:
(1)点扩展插件,输入MySQL,安装第一个,如图。
 (2)打开左侧资源管理器,点+号,分别录入host、user、password、port,最后一个回车即可,我这里对应的是localhost、root、root、3306。然后就轻松建立一个localhost连接了。
(2)打开左侧资源管理器,点+号,分别录入host、user、password、port,最后一个回车即可,我这里对应的是localhost、root、root、3306。然后就轻松建立一个localhost连接了。
 注意:如果连接不成功,下面有Error提示的话,一般要更新一下password,才能连接。命令如下:
注意:如果连接不成功,下面有Error提示的话,一般要更新一下password,才能连接。命令如下:
alter user ‘root’@‘localhost’ identified with mysql_native_password by ‘root’; - 用PyCharm连接数据库的方法,相对也很简单。
(1)单击右侧数据库,再点+号,再点MySQL即可建立。
 (2)在弹出的对话框中,输入相应的参数。
(2)在弹出的对话框中,输入相应的参数。

3.5.4 程序全部代码
# -*- coding:utf-8 -*- """ # @Time:2022/12/19 0019 13:53 # @Author:晚秋拾叶 # @File:链家长沙房源.py # @PyCharm之Python # 完成“标题,位置,户型,总价,单价”几个信息的收集并保存 """ import requests import pymysql from pyquery import PyQuery as pq class LianJian_changsha(object): def __init__(self, num): self.url = 'https://cs.lianjia.com/ershoufang/pg{}/'.format(num) self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54', } # 创建数据库连接 self.db = pymysql.Connect( host="localhost", port=3306, user="root", password="root", db="lianjia" ) # 再创建数据库游标 self.cursor = self.db.cursor() ''' 1. 发起请求并获取数据 ''' def get_data_index(self): # 可以使用urlli库里的方法from urllib.request import Request # 即用urllib中的request模块里的Request类定义解析的网页数据, # 不过需要用read()读取二进制内容,再用decode('utf-8')转为Unicode编码 # 所以不如requests库来得方便 """ (1)用到第一个库requests的get方法,获取总的网页源代码 """ resp = requests.get(self.url, headers=self.headers) resp.encoding = 'utf-8' if resp.status_code == 200: return resp.text else: return None ''' 2. 把得到的网页文本信息进行解析 ''' def parse_data_index(self, resp): # 进一步筛选想要的源代码内容,缩小范围 """ (2)还是用xpath定位好范围 """ doc = pq(resp) sellListContent = doc(".sellListContent li") for data in sellListContent.items(): # 下面用了CSS选择器,加上text方法获取文本内容 title = data(".info.clear .title a").text() position = data(".info.clear .flood").text() houseInfo = data(".info.clear .houseInfo").text() priceInfo = data(".info.clear .totalPrice.totalPrice2 span").text() + "万元" unitPrice = data(".info.clear .unitPrice span").text() # 定义sql语句,以便下面执行插入操作 sql = "insert into lianjia_cs (title,position,houseInfo,priceInfo,unitPrice) values(%s,%s,%s,%s,%s);" # 把信息字段写入参数 params = [(title, position, houseInfo, priceInfo, unitPrice)] # 执行语句 self.cursor.executemany(sql, params) # 提交数据库 self.db.commit() """ 3. 把上面方法整合起来完成业务逻辑""" def run(self): resp = self.get_data_index() # 获取网页信息 self.parse_data_index(resp) if __name__ == '__main__': # 爬取前5页的数据 for n in range(1, 6): spider = LianJian_changsha(n) spider.run()- 结果如图。

3.6 parsel方法
- 这次用parsel方法,把这个任务完成。这个方法,其实很简单,提取到网页源代码后,还是应用了xpath方法。不过这次数据,我再用MongoDB数据库保存。
3.6.1 安装MongoDB
-
安装包下载地址:https://www.mongodb.com/try/download/community

-
step1:打开安装包直接点击Next

-
step2:继续点击Next

-
step3:点击自定义安装

-
step4:选择好安装路径,点击Next

-
step5:点击Next

-
step6:取消可视化界面勾线,直接点击Next安装

3.6.2 初始化MongoDB
-
step1:配置环境变量,找到MongoDB安装路径下的bin目录

-
step2:计算机--右击--属性--高级系统设置--环境变量--系统变量--path--新建,将bin目录复制进去即可
 补充:进到data目录里面,新建两个文件夹,一个是db,一个是log
补充:进到data目录里面,新建两个文件夹,一个是db,一个是log -
step3:打开cmd,输入mongod -dbpath "F:\MongoDB\data\db" -logpath "F:\MongoDB\data\log\mongo.log"

-
step4:重新打开一个cmd窗口,输入mongo来启动MongoDB shell 端 这里遇到一个问题就是,我安装的是高版本的MongoDB,显示mongo命令不存在。
 查了一番资料,才明白,高版本已经没有这个命令了。然后根据资料提示,重新下载一个mongosh文件代替。
地址:https://www.mongodb.com/try/download/shell
查了一番资料,才明白,高版本已经没有这个命令了。然后根据资料提示,重新下载一个mongosh文件代替。
地址:https://www.mongodb.com/try/download/shell

-
下载解压后,找到bin目录,把这两个文件,复制粘贴到MongoDB下的bin目录。


-
再执行mongosh命令就行了。

-
**step5: 创建一个数据库,再建立一个集合 ** 创建\删除数据库
use db_lianjia # 如果数据库不存在,则创建数据库,否则切换到指定数据库。 db.dropDatabase() # 删除数据库之前,先进入数据库,之后执行 # 删除当前数据库实例:
>use db_lianjia switched to db db_lianjia >db db_lianjia如果你想查看所有数据库,可以使用 show dbs 命令:
> show dbs admin 0.000GB config 0.000GB local 0.000GB可以看到,我们刚创建的数据库 db_lianjia并不在数据库的列表中, 要显示它,我们需要向 db_lianjia 数据库插入一些数据。
增删改查操作
MongoDB中的一张表被称为一个集合
插入数据
- 语法:
# db.集合名.insert({}) 数据格式为json db.demo.insert({name:"坤哥"}) # { "_id" : ObjectId("63465fb77811f81334940270"), "name" : "坤哥" }上面的命令执行完,就自动创建了一个demo表。总结上面的命令如下图:

- 我后面接着连接数据库,进行一个集合的实例,进一步理解上面的操作。
3.6.3 数据库与IDLE的连接操作
- 连接MongoDB时,需要使用PyMongo库里面的MongoClient方法,格式如下:
import pymongo client = pymongo.MongoClient(host='localhost', port=27017) - 上面语法用来创建MongoDB的连接对象。
- (1)PyCharm下安装MongoDB插件。
-
点击右侧的数据库,一步步点击

-
下一步,输入名称:MongoDB,主机:localhost,再点击下方的“下载”,最后完成测试连接。
 注意:这里反复下载提示重试,最后发现,需要github账号。
注意:这里反复下载提示重试,最后发现,需要github账号。 -
终于下载并连接成功了。

-
- (2)再用VSCode连接一下。
-
点扩展,再搜索mongo,如图下载MongoDB for VS Code:

-
再点左侧出现的数据库,然后点CONNECTIONS右侧的+号。

-
出现New connection之后,输入localhost,再输入账号、pwd以及本地数据库的名称。

-
- 提示,账号密码的设置在管理员console命令中,分如下几步完成。
- mongosh # 打开MongoDB;
- use db_lianjia # 创建或打开数据库;
- db.createUser({user: "root", pwd: "root", roles: [{role: "root", db: "admin"}]}) # 修改用户和密码

- 最后也完成VSCode下的MongoDB的连接。

3.6.4 程序全部代码
# -*- coding:utf-8 -*- """ # @Time:2022/12/19 0019 13:53 # @Author:晚秋拾叶 # @File:链家长沙房源.py # @PyCharm之Python # 完成“标题,位置,户型,总价,单价”几个信息的收集并保存 """ import requests import pymongo from parsel import Selector class LianJian_changsha(object): def __init__(self, num): self.url = 'https://cs.lianjia.com/ershoufang/pg{}/'.format(num) self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54', } # 创建数据库连接 self.client = pymongo.MongoClient(host="localhost", port=27017) # 再创建一个数据库,下面命令执行的时候,是没有创建,有则连 self.db = self.client["db_lianjia"] ''' 1. 发起请求并获取数据 ''' def get_data_index(self): # 可以使用urlli库里的方法from urllib.request import Request # 即用urllib中的request模块里的Request类定义解析的网页数据, # 不过需要用read()读取二进制内容,再用decode('utf-8')转为Unicode编码 # 所以不如requests库来得方便 """ (1)用到第一个库requests的get方法,获取总的网页源代码 """ resp = requests.get(self.url, headers=self.headers) resp.encoding = 'utf-8' if resp.status_code == 200: return resp.text else: return None ''' 2. 把得到的网页文本信息进行解析 ''' def parse_data_index(self, resp): # 进一步筛选想要的源代码内容,缩小范围 """ (2)如同前面章节提到的,SelectorList对象再用CSS选择器选择的属性, 先是被转成了xpath,所以这里还是用xpath定位匹配文本 """ # 创建一个Selector对象 st = Selector(resp) # 创建一个SelectorList对象 sellListContent = st.css(".sellListContent li") i = 0 for data in sellListContent: title = data.xpath('.//div[@class="title"]/a/text()').get() position = ",".join(data.xpath('./div[1]/div[2]//a/text()').getall()) houseInfo = data.xpath('.//div[@class="houseInfo"]/text()').get() priceInfo = data.xpath('.//div[contains(@class,"totalPrice")]/span/text()').get() + "万元" unitPrice = data.xpath('.//div[@class="unitPrice"]/span/text()').get() yield {'标题': title, '位置': position, '户型': houseInfo, '总价': priceInfo, '单价': unitPrice} """ 3. 把上面方法整合起来完成业务逻辑""" def run(self): resp = self.get_data_index() # 获取网页信息 parse_data = self.parse_data_index(resp) for item in parse_data: print(item) self.db.lianjia_cs.insert_one(item) if __name__ == '__main__': # 爬取前5页的数据 for n in range(1, 6): spider = LianJian_changsha(n) spider.run()
- 用db命令也能查看数据已经写入。

4. 面向对象的写法总结
- 面向对象的编程,能够让你的思路条理化。上面几种爬虫库完成既定目标,都是基于这个思想。
- 首先,都是建立一个类,包含要抓取的网页的地址,伪装和各种数据库的连接等等。
- 再写几个重要的方法。分别是获取网页数据、用各种爬虫库里的方法对网页数据进行解析、写入各种形式的保存方式的类方法、整合运行的类方法、调用类的主程序。。。
4.1 获取网页数据
- 这部分代码,所有的爬虫库都用到requests里的get方法,不过,遇到大型数据的爬取,就有点力不从心了。好在后面还会学到更强大的处理方法。
- 这里不管是得到的是什么数据,都要保证返回不为空,否则后面的工作也就成空了。
4.2 网页数据解析提取
- 这个题目中的要求,基本没有字典形式的数据,也没有抓取图像和音视频的情况,如果有的话,自然用xpath和bs4更方便一些。
4.3 遍历源代码数据列表
- 这个题目中,网页数据解析的时候,只是缩小范围,再得到列表,用遍历的for语句,结合各种方法得到一条一条的数据了。至于什么时候用return返回数据,还是用yield生成器,则要看保存的形式和地方了。
4.4 数据保存的问题解决
- 保存的方式,从简单的控制台打印,到文本文档,csv格式,再到稍复杂的csv和excel格式,一直到两种数据库MySQL和MongoDB的形式,一遍一遍改写和测试,加上我这新手不熟悉不断的找寻各种问题解决的资料信息,一共花费了近4天的时间,终于完成这部分知识的笔记。
4.5 业务逻辑的实现
- 再总结一个问题,就是业务逻辑的实现。主要是在run方法里面完成,翻页的效果,除了bs4这个方法结果保存为excel表格要处理翻页,其它的都在main主函数里面for循环完成。
- bs4这段中,为了追加成功,把这个功能写到了解析的类方法parse_data()里面,然后少了写的方法write_data()了。
4. 总结
- 上面写得太多,不总结了。总结一句,就是学习的过程,如柳暗花明,如众里寻他,如漫漫轻云,又如南朝四百八十寺,更如春风又绿江南岸。


